- Published on
Why I'm Obsessed With Search
- Authors
- Name
- Kumar Shivendu
- @KShivendu_




I've been building search systems for a few years now: search over 420M+ software repositories, distributed systems that power billion scale vector search at Qdrant and run on hundreds of thousands of machines all over the world, and reverse-engineering how Exa does web scale search.
This post will tell you why I care so much about search. My hope is that it either convinces you to work on search or helps you find your own thing to be obsessed about.
What do I mean by search here?
The word "search" gets used loosely, so let me narrow it down. Three things often get lumped together under this label:
- Optimization: Any kind of optimization can be called "search," and it's related to what the Bitter Lesson talks about. Interesting, but not what I mean here.
- Querying: "which rows match these exact filters?" What databases are built for.
- Retrieval: "for this fuzzy intent, what results are most relevant?" This is what I mean.
Querying returns everything that matches. Retrieval decides what matters most. That requires understanding intent and separating signal from noise.
Search is everywhere and shapes our lives
Search is the most embedded technology in modern life: finding information, ordering food, hunting houses, discovering people and products, writing code. Think Google, YouTube, Amazon, LinkedIn, etc.
It's everywhere, and its quality shapes what we know and what we believe is possible. And yet useful information, great products, people worth knowing are often not discovered because search isn't perfect (yet?).
Search is how curiosity becomes knowledge

I'm naturally very curious and curiosity generates questions. Search provides answers to those questions. Answers lead to knowledge when absorbed well. And eventually that knowledge leads to more questions. Search is the engine for compounding knowledge. The better the feedback loop between question and answer, the faster you learn.
Search is a tool that amplifies our cognitive capability
Humanity has flourished by building tools to overcome its biological limits: planes because we couldn't fly, submarines because we couldn't breathe underwater, photos because memory is fallible. When someone builds a great tool and gives it to the rest of society, the impact compounds.
The human brain is remarkable at pattern recognition (also a kind of search), storage, and compression, but no human can store and rank billions of documents within milliseconds. Search is a tool for the mind that makes this possible. It narrows an incomprehensibly large space down to the handful of things actually worth our attention.
How search shaped my own path
I grew up in a small town in India. When we finally got internet on our computer, Google was the first thing the computer guy showed me, and it became my gateway to a whole new world.
Without any books, courses, or mentors, I learnt programming at the age of 13, entirely by searching. I'd type half-formed questions into Google like "how to add button in VB.net" and land on forums like SourceForge, CodeProject, or W3Schools. I'd download source code of applications, do Ctrl+F, and figure out how things worked.
When Chrome launched, it felt like a leap from Internet Explorer: fast, clean, and search built right into the address bar. Then came voice search, and saying "OK Google" felt like having my own Jarvis. I remember spending hours exploring everything it could do.
Looking back, search is the reason I could teach myself to code at an early age. It took me years to realize that "how does Google search actually work?" was one of my earliest curiosities, and looks like I've been thinking about the same recently.
Search is a hard problem worth solving
Search sits at the intersection of data structures, distributed systems, performance, and machine learning (some of the hardest areas in computer science). Mastering search forces you to go deep on all of them.
What makes search even more unique is the tension between signal and noise. You're not just finding matches, you're ranking them. That means modeling relevance, which means understanding intent, which means wrestling with ambiguity. "Apple" could mean the fruit, the company, or the record label, and the system has to figure it out. And ranking isn't purely technical. Business decisions like sponsored results and content policies add more complexity.
Search also sits at the top of the user funnel with some of the highest query volumes in most products, so scale magnifies every mistake. This combination builds deep intuition and taste that generalizes broadly.
Search queries are a window into collective intent
Aggregate search queries are a real-time map of what humanity is curious about. What people search is what they're thinking, feeling, or worried about at any given moment. Understanding those query patterns, search journeys, and how needs evolve over time, and then zooming out to community, country, and global scale, is genuinely one of the most amazing things for me.
I love checking out trends.google.com and marveling at the insight that emerges from aggregate search signals. For example, during COVID-19, searches for "loss of smell" spiked across countries before it was even recognized as a symptom. Aggregate search data has also predicted election outcomes, box office hits, and economic downturns before official indicators caught up. Google/Perplexity, Amazon/Flipkart, Opentable/Zomato, Zillow/NoBroker, Pinterest/Instagram. Every search team sits on a window into how the world thinks within their verticals.

I'm a data nerd
I collect data I have no immediate use for. It's just the pull of "I wonder what's actually in there." I've scraped Zomato menus, gated societies in India, tech events in Bangalore, docker pull counts for devtool startups, and more. I inspect network traffic (or reverse-engineer) undocumented APIs to see how systems organize their data and what they choose not to expose. One-off scrapes never felt like enough. I wanted the stream, not the snapshot. So I built pipelines to monitor my own life: coding time, screen usage, health data. Ps. I deeply care about everyone's privacy so it's always public data or my own.
Once you have data, the natural first move is stats and visualization. Querying is what actually brings data to life: it turns a passive artifact into something you can interrogate. Dashboards and filters do that, but only for the questions you thought to ask upfront. Search is the most accessible and expressive type of querying, and it captures the fuzzy, semantic questions that no filter or chart could anticipate. Anyone can walk up to a dataset and ask something new, in their own words, and get something meaningful back. That's what makes data feel alive.
The Duality of Search & Generation
This is more about nature of the universe and information than just humanity. I always had the abstract thought but this blog by Han Xiao (Co-founder, Jina AI) gave me the right words.
Search is Overfitted Generation; Generation is Underfitted Search
At one extreme, search is like an overfitted generator: constrained to what already exists in an index, optimizing for fidelity to known items. At the other extreme, generation is like an underfitted search system: it can improvise and compose new outputs but may drift from grounded truth.
I find this extremely fascinating. Here's a diagram from the blog that explains what I mean. You can swap ??? with either search or generate. Can you even tell the difference below? Which ones are search results and what are generated results? Does it even matter as long as it solves your need?
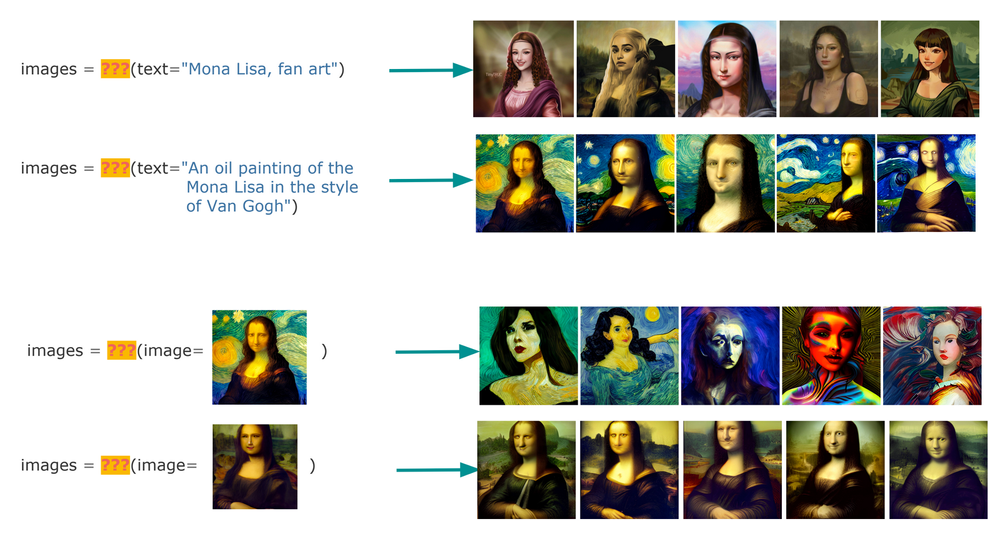
You can also try out lexica.art which brings this example to life!
Future of search
Search has three things to trade off: speed, quality, and cost. Quality is the hardest to measure, but it's the one that matters most. High-speed, low-cost search that returns the wrong thing just wastes the user's time more efficiently. Yet many companies optimize for cheap and deliver poor experiences as a result.
But one thing is shifting: latency tolerance. Users are increasingly willing to wait a few seconds longer for results that are actually right. That tolerance is quietly unlocking a different design space.
Here are the directions I think will define the next era of search quality:
Agentic search: Iteratively decomposing queries into sub-searches, evaluating intermediate results, and deciding what to search next based on findings. The real unlock is the number of iterations: it makes quality, cost, and latency tunable tradeoffs on a query level. This is already happening with Perplexity, Cursor, Exa, Parallel, etc and will go beyond web/code search.
Personalization at depth: Search that knows your history, mental model, and current context will outperform search that treats every query as cold-start. AI agents like Claude and OpenAI now have memory which allows them to perform better search. The gap between "search for anyone" and "search for you" is enormous.
Better representations: We went from sparse BM25 to dense embeddings to late interaction. ColBERT-style models compare query and document at the token level, making it essentially an attention mechanism applied during retrieval. Multi-vector models now allocate vectors based on information density rather than token count.
Unified search and generation: Retrieval systems and generative models are both storing knowledge, just at different compression levels. RAG and agentic search are already blurring this boundary, and with continual learning, the system itself will decide where a piece of knowledge lives on this spectrum and how to surface it.
Closing
Every search query is a hope that the right information exists and can be found. Better search doesn't just save time. It shapes how you think, what you choose, and what you dare to imagine.
Few problems have such impact. And that's why I'm obsessed with search!